반응형
논문 : https://arxiv.org/abs/1708.05031
Background
1. Learning From Implicit Data
- Implicit Data가 없는 경우 : 인지X or 부정적으로 평가
- data가 없는 이유를 구분하기 어렵기 때문에 item 간 순위를 선정할 경우 noise 발생
- 목적 함수
- pointwise loss : 실제와 예측 간의 오차를 감소시키는 방향으로 학습
- 유연하게 negative sample 비율 조정 가능
- pairwise loss : 관측된 경우와 관측되지 않은 경우 간의 margin을 최대화하는 방향으로 학습
- 관측된 경우의 순위가 관측되지 않은 경우의 순위보다 높음
- pointwise loss : 실제와 예측 간의 오차를 감소시키는 방향으로 학습
2. Matrix Factorization
- 잠재 feature 벡터를 이용해 공유된 잠재 공간에 user, item을 projection
- 상호작용 : 잠재 벡터 간의 inner project을 통해 모델링

- figure1
- a : user 4는 user 1, user 3, user 2순으로 유사하다
- b : 잠재 공간에 매핑 시 p4(user 4)를 p1과 가깝게 둘 경우, p3보다 p2와 가까워진다.
- 특징
- user, item 잠재 요인의 양방향 상호작용 모델링
- 차원 간 독립성을 가정하며, 같은 가중치로 user와 item을 선형 결합
- user와 item을 같은 공간에 mapping → user 간 유사도 측정 가능
- 저차원에서 간단하고 고정된 방식의 inner project로 복잡한 상호작용을 추정
→ 잠재 공간에 mapping 시 ranking loss 가 커진다
- 선형 상호작용 모델링 함수의 간단함으로 인해 성능 개선에 한계
- 잠재 요인 K가 많아지면 ranking loss가 감소하지만 일반화가 어려워진다
기존 연구
- 평점 예측 시 explicit feedback 사용
- 상위 K개 추천 : implicit feedback도 함께 사용
- 가중치 부여 방식에 따른 성능 연구
- DNN 적용한 추천시스템
- explicit data만 이용 : Implicit data를 통한 사용자 선호도를 학습하지 못함
- RBMs : 평점 모델링
- autoencoder
- AutoRec : 사용자의 과거 평점 이용
- DAEs : 오염된 정보 이용 for 일반화 가능성
- 보조적인 정보 모델링 시 DNN 활용 : 상호작용 모델링 시에는 여전히 inner project 사용
- CDAE : Implicit data를 사용하지만 상호작용 모델링 시 linear kernel 사용
- NTN : 신경망을 이용해 상호작용 모델링하지만 동일한 embedding layer 사용
- Wide & Deep : 다양한 feature 통합에 집중
- explicit data만 이용 : Implicit data를 통한 사용자 선호도를 학습하지 못함
논문
General Framework

- CF의 full neural treatment를 위해 다중 레이어 사용
- input : user, item의 id를 one hot encoding한 값
- 콘텐츠 기반, 이웃 기반 등 다양한 방식에 맞춰서 사용 가능
- embedding layer : fully connected layer
- sparse 벡터를 dense 벡터로 변환
- dense 벡터 = latent 벡터
- Neural CF layer : 잠재 벡터를 예측 점수로 mapping
- 각 layer : 특정 잠재 structure를 파악하도록 맞춤 가능
- 마지막 은닉층 차원 : 모델 capability 결정 → 마지막 은닉층 = predictive factor
- output : 평점을 예측하고 pointwise loss를 최소화하도록 학습
- 단, DNN을 사용함으로써 pairwise loss도 사용하게 된다
GMF : Generalized Matrix Factorization
- MF : NCF의 특별 케이스
- NCF 프레임워크 이용 시 쉽게 MF 확장 및 일반화 가능
- GMF : 일반화된 MF
- GMF layer의 input : element-wise product된 MF vector
- sigmoid 함수를 이용
- 각 잠재 차원에 다른 가중치를 적용
- 잠재 벡터의 중요도 조절
MLP : Multi Layer Perceptron
- 비선형성 상호작용 모델링을 위해 MLP 이용
- user, item feature 단순 concat 시 상호작용을 포착하지 못함
- MLP를 이용하여 concated 벡터에 은닉층 추가
- 보다 복잡한 관계 표현 가능
- 성능 : ReLU > tanh > sigmoid
- ReLU : 과적합 위험이 적으며 sparse data에 적용하기 좋다
Fusion of GMF and MLP

- GMF : 잠재 feature 상호작용 모델링을 위해 linear kernel 적용
- MLP : 상호작용 함수 학습을 위해 비선형 kernel 적용
- GMF, MLP 앙상블
- 방법1 : 같은 embedding layer 사용
- 임베딩 크기가 같아야함 → 성능 한계
- 방법2 : 마지막 은닉층 concat
- NeuMF : Neural Matrix Factorization
- user, item 간 latent structure 모델링을 위해 MF(GMF) + DNN(MLP)
- 방법1 : 같은 embedding layer 사용
- 사전학습
- ReLU : non-convexity(미분 불가능한 첨점 존재)로 인해 gradient 기반 최적화 방식 사용 시 전역적인 최적값을 찾을 수 없다
- 사전학습된 GMF, MLP를 이용하여 NeuMF를 초기화
- GMF, MLP : 무작위로 초기화된 값으로 수렴할 때까지 학습
- optimizer : ADAM
- 훈련된 모델의 파라미터를 NeuMF에서 활용
- optimizer : SGD
- 두 모델의 가중치 concat : $\alpha$ 는 두 모델의 가중치 간 tradeoff를 조정하는 파라미터
- ReLU : non-convexity(미분 불가능한 첨점 존재)로 인해 gradient 기반 최적화 방식 사용 시 전역적인 최적값을 찾을 수 없다

Experiment
settings
- data
- MovieLens : 평점 정보를 0,1의 암묵적 정보로 변환
- Pinterest : sparsity problem을 해결하기 위해 최소 20번 이상의 상호작용 데이터가 있는 user만 포함
- train_test_split
- test : 가장 최근 상호작용 / 나머지는 train
- 아이템 순위 선정
- 상호작용이 없던 100개 아이템 간 test item의 순위 선정
- 상위 10개 아이템 중 test item 존재 여부 및 test item의 순위를 기반으로 평가
predictive factor 개수에 따른 성능 변화

- NeuMF, GMF, MLP 외 비교 모델
- ItemPop : 상호작용 수에 따른 인기도로 순위 결정 → 개인화되지 않은 결과 도출
- ItemKNN : 기본 아이템 기반 CF
- BPR : pairwise loss에 최적화된 MF
- eALS : 상호작용X은 negative로 간주하는 MF → item 기반 가중치 부여
- NeuMF : SOTA 달성
- GMF, MLP : NeuMF만큼은 아니지만 좋은 성능
- GMF 성능 > MLP 성능 : 단, MLP 은닉층 추가 시 성능 향상
- GMF vs eALS : 적은 predictive factor에서 GMF > eALS
- GMF vs BPR : 같은 MF이지만 목적함수가 다르기 때문에 GMF > BPR
- eALS vs BPR : 데이터에 따라 다른 결과
- Pinterest : BPR은 pairwise 순위 학습에 민감하기 때문에 순위 판단(NDCG) 시 좋은 성능
- 모델 기반의 다른 모델 > 이웃 기반 ItemKNN
상위 K개 추천에서 K에 따른 성능 변화

- NeuMF : SOTA 달성
- 사용자의 개인적인 선호를 고려하는 것이 필수적이기 때문에 ItemPop이 가장 나쁜 성능을 보임
- 사전학습된 NeuMF가 NeuMF보다 좋은 성능 : 사전학습의 필요성
- eALS vs BPR : 데이터에 따라 다른 결과
- Pinterest : BPR은 pairwise 순위 학습에 민감하기 때문에 순위 판단(NDCG) 시 좋은 성능
- 모델 기반의 다른 모델 > 이웃 기반 ItemKNN
Log Loss with Negative Sampling
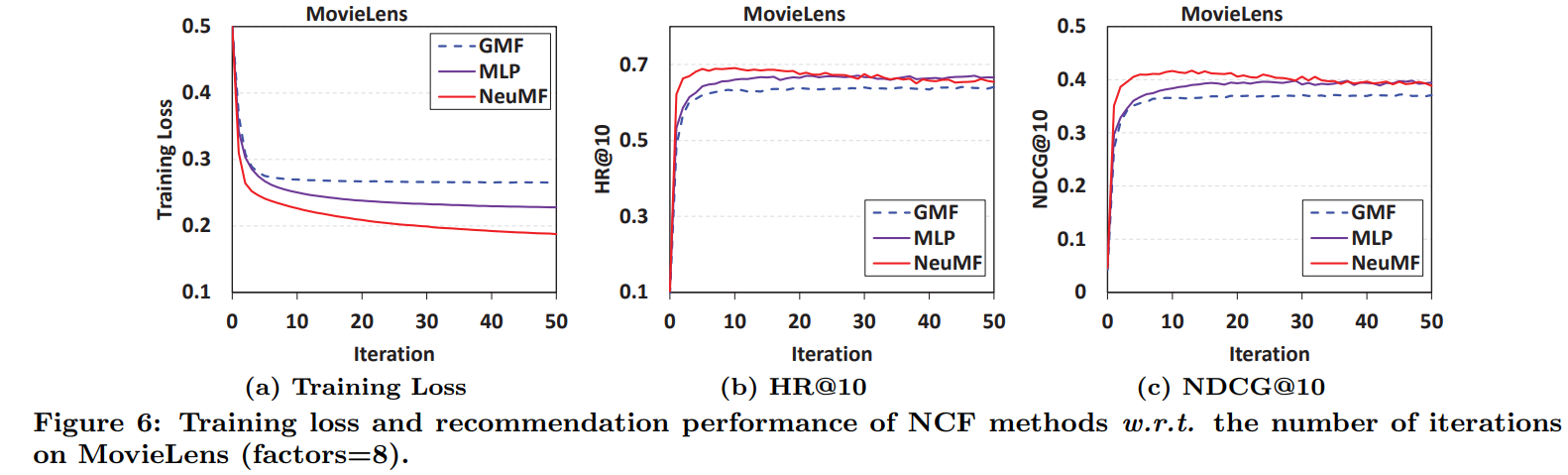
- iteration 증가 시 loss 감소
- 단, iteration이 10 이상인 경우 overfitting으로 추천 성능(HR, NDCG) 감소(정확성은 증가)
- NCF 간 성능 비교 : NeuMF > MLP > GMF
- log loss 최적화의 효율성으로 NeuMF가 좋은 성능을 보임

- negative sample이 1개인 경우 : GMF, BPR 성능 유사
- BPR : 하나의 negative instance만 포함
- negative 비율이 높은 경우 GMF > BPR
- pointwise log loss 사용 시 성능이 pairwise log loss 사용 시 성능보다 좋다
- GMF : pointwise log loss 사용
- BPR : pairwise log loss 사용
- 단, negative sampling 비율이 너무 큰 경우 성능이 저하
Is Deep Learning Helpful?
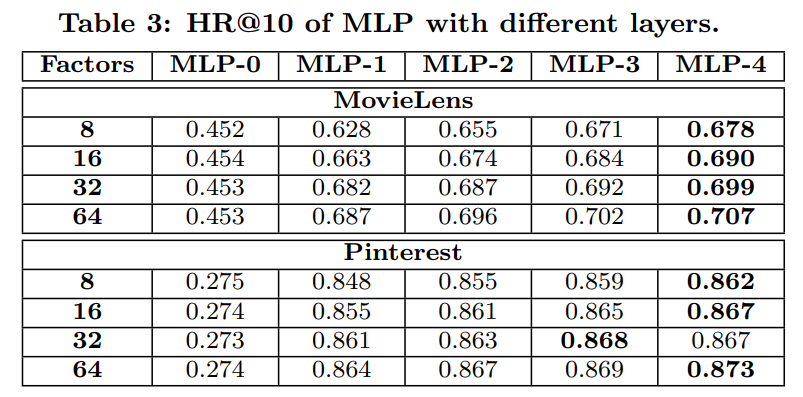
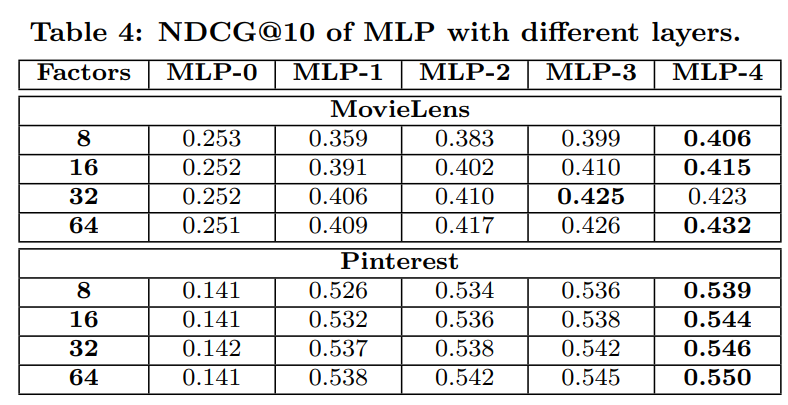
- 은닉층이 깊어질수록 성능이 향상된다
- 비선형인 ReLU 대신 선형 layer 사용 시 성능 저하
- 은닉층을 이용한 상호작용 변환이 필수적 : 은닉층을 적용하지 않을 경우 ItemPop보다 낮은 성능
결론
- GMF, MLP, NeuMF : 사용자와 아이템 간 상호작용을 모델링
- 간단하면서도 일반화 가능한 모델
- 추천시스템에 딥러닝을 적용하는 가이드라인을 제시했다는 데에 의의